Reinforcement Learning based Control
of a Race Car
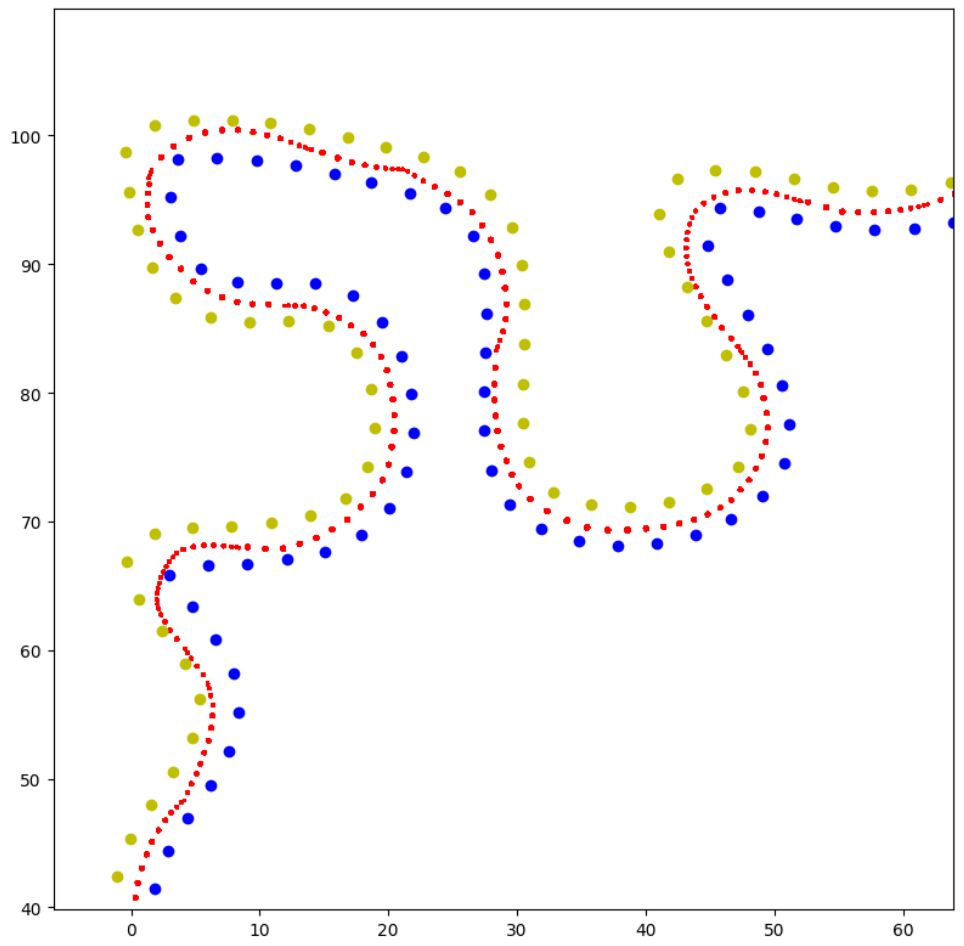
I left some information to keep the title in an accessible length. This was my term project at the Formula Student team of my university. Currently their driverless car is controlled by a polynomial trajectory planning system. The experiment is to see if a reinforcement learning (RL) trained neural network can control the car with better performance than the current system. For this purpose a simulator and a RL training system was created last year. The outcome of nine months of work is a simplified and functioning training system. It produced a policy that finishes a specific track in every fifth run. An illustration of the driven trajectory can be seen below.
Major developments are:
- The introduction of the Ray RLlib framework to replace the hand-implemented algorithm. RL training systems generally consists of an environment (represented by a simulator) and the actual RL algorithm. By adhereing to a defined interface, one can easily use the same algorithm implementation for different environments. The framework simplifies the project and lowers the risk of implementation errors in the RL algorithm significantly.
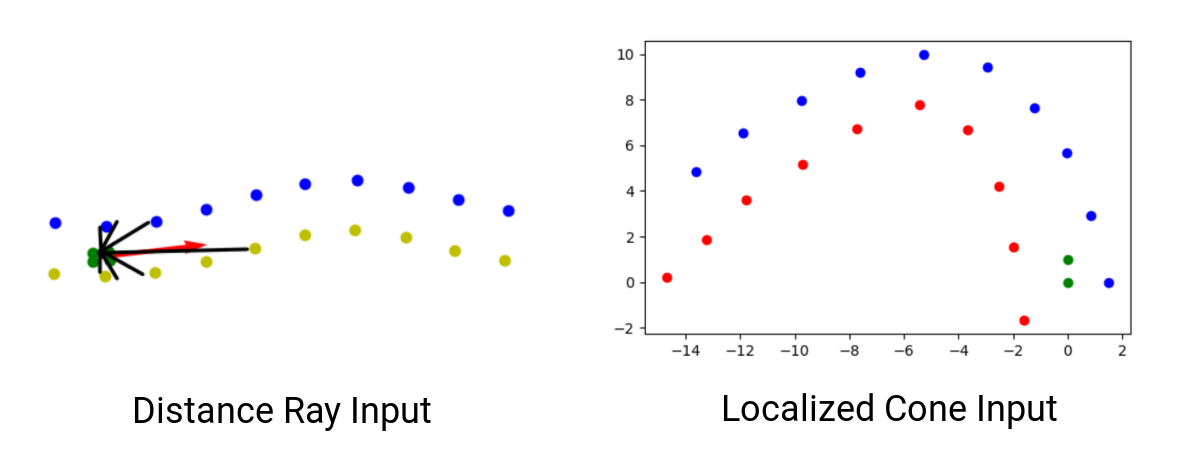
- The input change from distance rays distributed over the field of view to the direct localized coordinates of the next ten cones on each side. The images below illustrates both concepts. The right image shows a plot of the next twenty cones in the field of view of the agent and how their coordintes are localized around the car.
- The approach of starting many trainings with differently scaled reward function components. In the end, the component combination that provides the best training results is used. The training results change quickly with minimal changes in reward parameters. Going through all combinations manually is not practicable.
The basically driving agent proved the concept that a neural network can learn to control the car from the given cone positions. The result also gives clear evidence that it is worth to continue working on the project.
With the current state of the project, it was not beneficial to compare the performance to the conventional system. As can be seen on the image above, the agent starts to drive ideal trajectories. But the distribution densitiy of the red plots shows that the agent often stops briefly and then accelerates fully again.
Nevertheless, for the goal of a better driving and generalizing neural network, the most important milestones have been identified. These include generating more training and test tracks, and further fine-tuning the reward function for the training with an optimized parameter evaluation script.
If you are interested in the details, take a look at my term project paper:
Term Project Paper
These are my personal lessons from the project besides the technical aspects:
- Undergoing the pain of a bad documentation is probably the biggest lesson for most of the students that take over projects - if they care, they will focus especially on a good documentation.
- In a team, if you work in your own speed as quick as you can, you dont leverage the benefit of having mates, and in the longterm you probably bust the project.
- Always ask the question what is currently the most important problem to solve to reach the goal. Do not run into pet projects just to show off "progress".
- My view of a good engineer changed from "mere" finding elegant solutions to: as an engineer your work is only as good as the documentation you provide to it. The work is only good when it is supposed to be build on it.
- If the project is difficult and complex, clarify your motivation and simplify the system (frameworks, cut out unnecessary modules).